Introduction
Our work is about improving the separation of a musical source - the singing voice - from a musical mixture, by using novel phase recovery techniques. Typical musical sound source separation methods are based only on the retrieval of the magnitude, and use the original mixture's phase to estimate complex-valued time-frequency representations of the sources. We propose to recover the phase of the separated sources by using more recent phase retrieval algorithms.
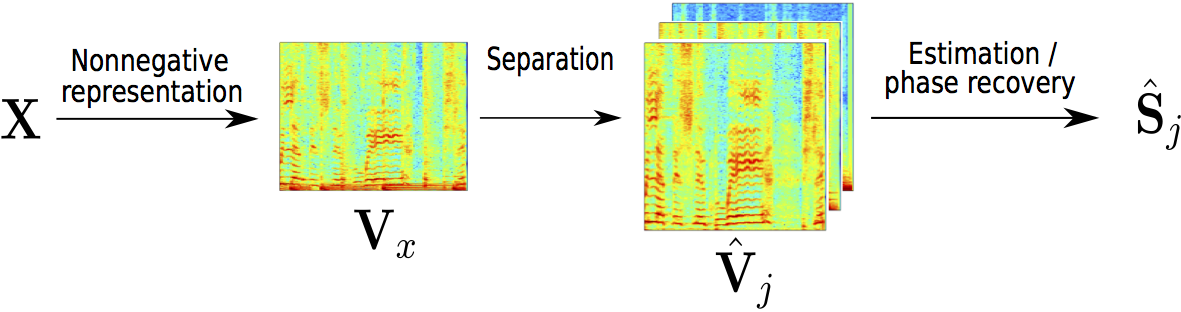
For evaluating our method, we focus on the singing voice separation. We are using the most state-of-the-art method, MaD TwinNet, to estimate the magnitude spectrogram of the singing voice. On top of that, we show that improved phase recovery algorithms reduce interference between the estimates sources (here: singing voice and musical background).
MaD TwinNet
MaD TwinNet offers current state-of-the-art results on monaural singing voice separation. For more details, visit MaD TwinNet's site!
In a nutshell, MaD TwinNet uses the Masker to retrieve a first estimate of the magnitude spectrogram of the targeted source. Then, it enhances this spectrogram with the Denoiser, producing the final estimate, $\hat{\mathbf{V}}_{1}$, of the targeted musical source. We use this final estimate as an input for phase recovery techniques.
Phase Recovery
In short, phase recovery is achieved by exploiting phase constraints that can originate from several properties:
- Property of the time-frequency transform: these transforms are usually computed with overlapping analysis windows, which introduces dependencies between adjacent time frames. For the case of the STFT, not every complex-valued matrix is the STFT of a time-signal (in other words, the STFT is not a surjective application). This mismatch can be measured by a function $\mathcal{I}$ called inconsistency and used to recover the phase of the STFT.
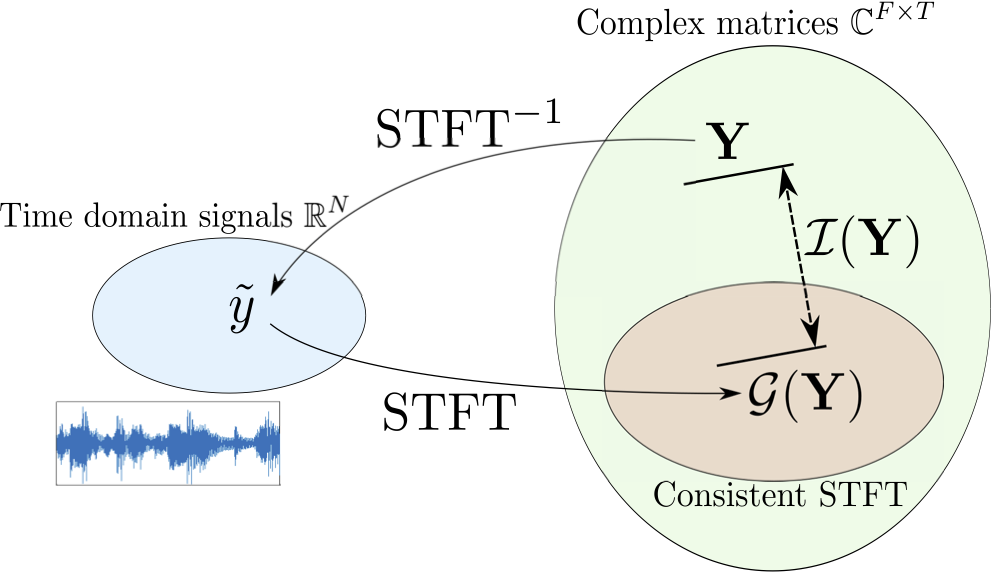
- Property of the signal itself: that is, the signal is assumed to follow a model from which we can obtain some information about the phase in the STFT domain. Here, we use the model of sum of sinusoids, from which a relationship (called phase unwrapping) between the phase of adjacent time frames can be obtained.
Those phase constraints can be incorporated into a source separation framework, in order to account for both prior phase models and the mixture's phase. Indeed, we want to promote some phase properties, but provided that the estimated sources will still add up to the mixture (in other words, we want to preserve the overall energy of the audio signal).
The first algorithm we propose is the recently-introduced consistent anisotropic Wiener filter. It is an extension of the classical Wiener filter that has been designed to account for the two phase properties presented above. More info on this filter here!
The second algorithm is an iterative procedure that uses phase unwrapping as an initialization scheme. Unlike Wiener fitlers, it does not modify the target magnitude over iterations. The iterative process is illustrated bellow, and more details can be found on the companion website of the corresponding journal paper.
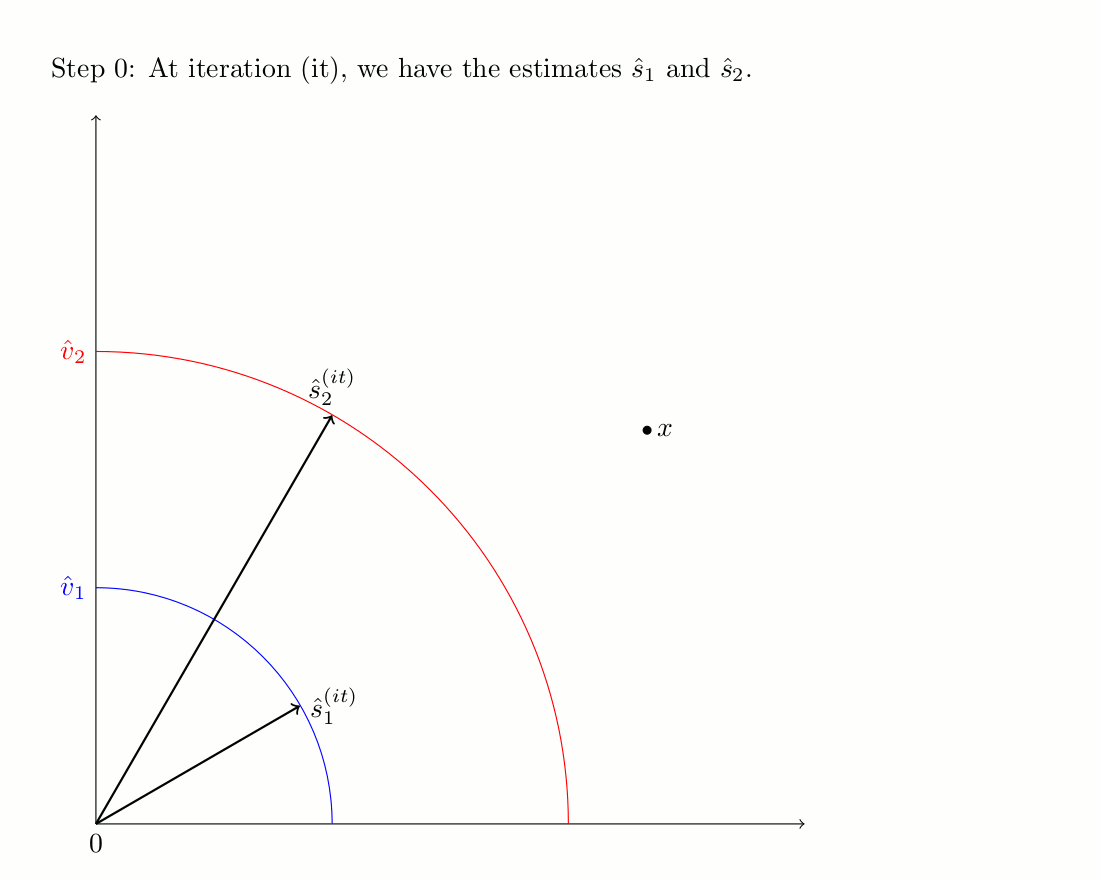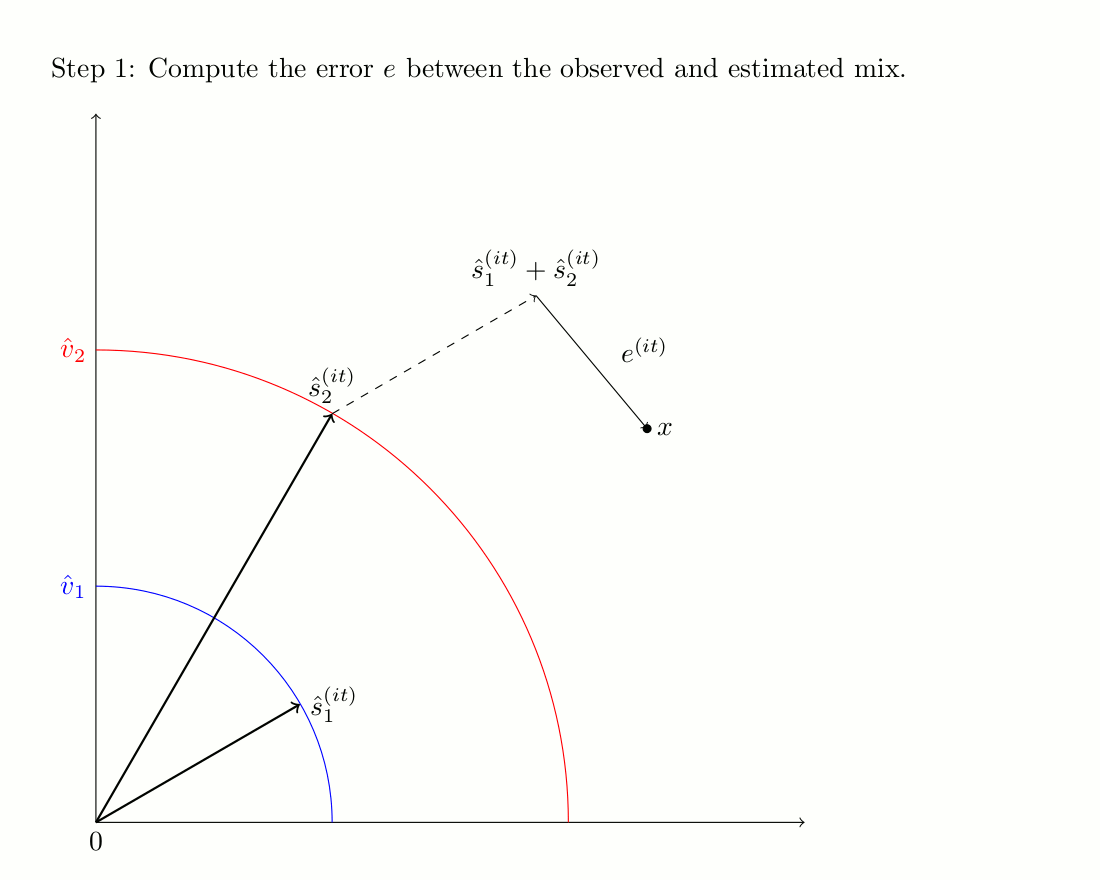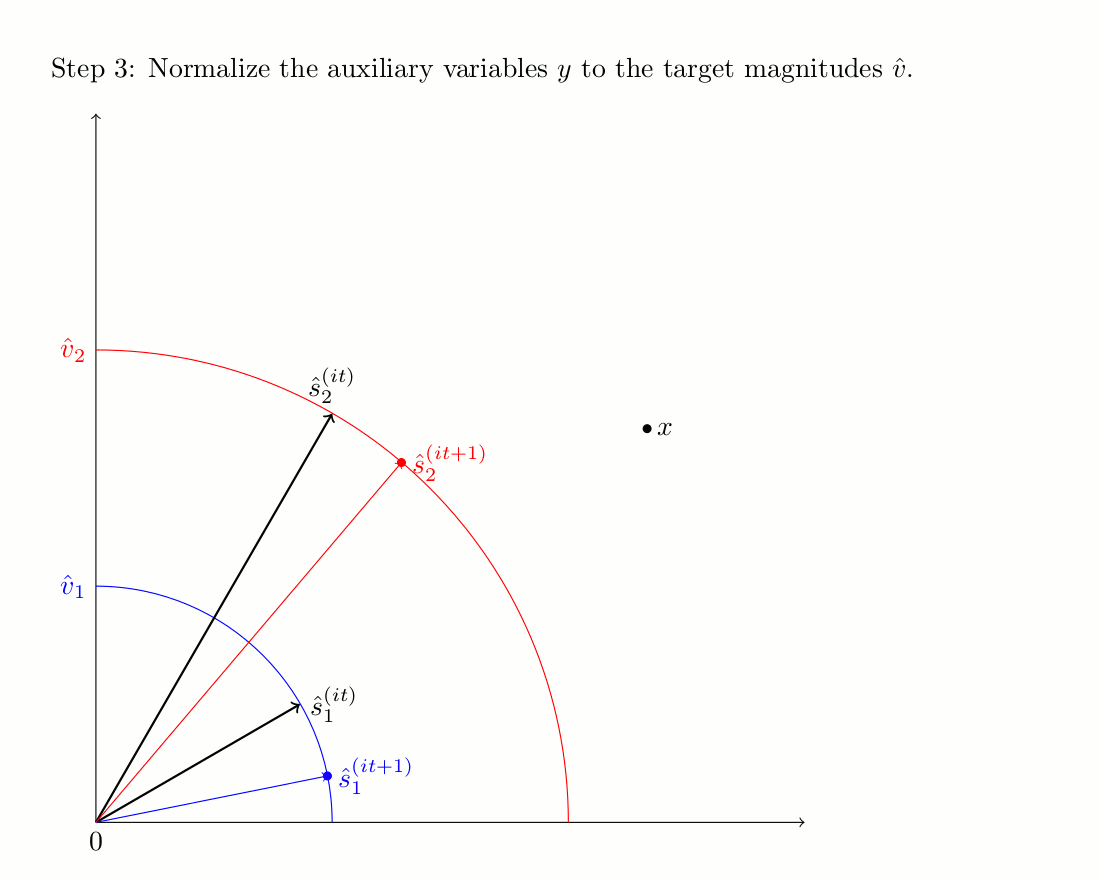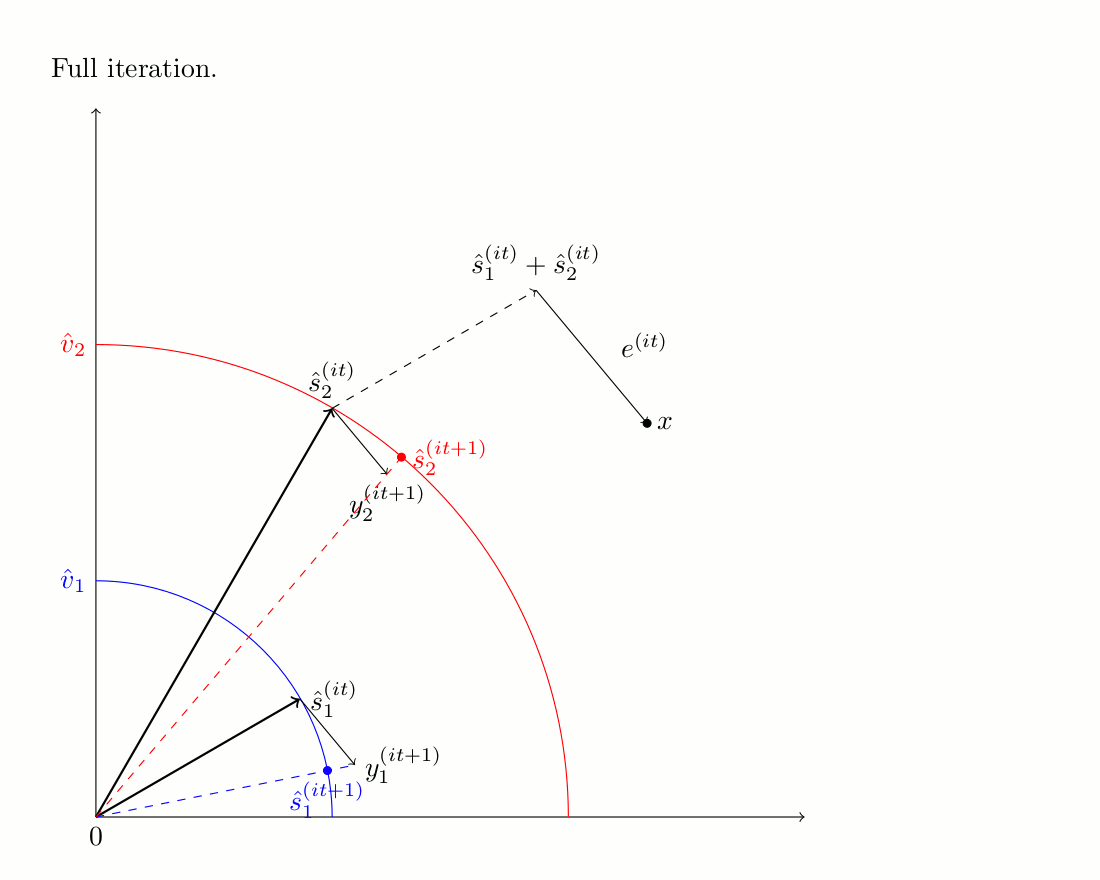
Demonstration
Below you can actually listen the performance of our method! We have a set of songs and for each one, we offer for listening the original mixture (i.e. the song), the original voice, and the predicted voice as is reconstructed by simply using the mixture's phase and by our algorithms.
To offer you the ability to compare the results of our algorithms, we used exact the same songs and excerpts with the results presented for the MaD TwinNet.
Must be mentioned that we did not do any kind of extra post-processing to the files. You will just hear the actual, unprocessed, output of our algorithms.
Original mixture
Predicted voice reconstructed using mixture phase
Predicted voice reconstructed using PU-Iter
Predicted voice reconstructed using CAW filtering
Original voice
| Artist | Title | Genre |
|---|---|---|
| Signe Jakobsen | What Have You Done To Me | Rock Singer-Songwriter |
Original mixture
Predicted voice reconstructed using mixture phase
Predicted voice reconstructed using PU-Iter
Predicted voice reconstructed using CAW filtering
Original voice
| Artist | Title | Genre |
|---|---|---|
| Fergessen | Back From The Start | Melodic Indie Rock |
Original mixture
Predicted voice reconstructed using mixture phase
Predicted voice reconstructed using PU-Iter
Predicted voice reconstructed using CAW filtering
Original voice
| Artist | Title | Genre |
|---|---|---|
| Sambasevam Shanmugam | Kaathaadi | Bollywood |
Original mixture
Predicted voice reconstructed using mixture phase
Predicted voice reconstructed using PU-Iter
Predicted voice reconstructed using CAW filtering
Original voice
| Artist | Title | Genre |
|---|---|---|
| James Elder & Mark M Thompson | The English Actor | Indie Pop |
Original mixture
Predicted voice reconstructed using mixture phase
Predicted voice reconstructed using PU-Iter
Predicted voice reconstructed using CAW filtering
Original voice
| Artist | Title | Genre |
|---|---|---|
| Leaf | Come around | Atmospheric Indie Pop |
Data and objective results
In other words, from what data is our method learned, on what data it is tested, and how well does it perform from an objective perspective?
Dataset
In order to train our method, we used the development subset of the Demixing Secret Dataset (DSD), which consists of 50 mixtures with their corresponding sources, plus music stems from MedleyDB.
For testing our method, we used the testing subset of the DSD, consisting of 50 mixtures and their corresponding sources.
Objective results
We objectively evaluated our method using the signal-to-distortion ratio (SDR), signal-to-interference ratio (SIR), and signal-to-artifacts ratio (SAR). The results for the singing voice can be seen in the table below.
| SDR | SIR | SAR | |
|---|---|---|---|
| Mixture's phase | 04.57 | 08.17 | 05.97 |
| PU Iter | 04.52 | 08.87 | 05.52 |
| CAW | 04.46 | 10.32 | 04.97 |
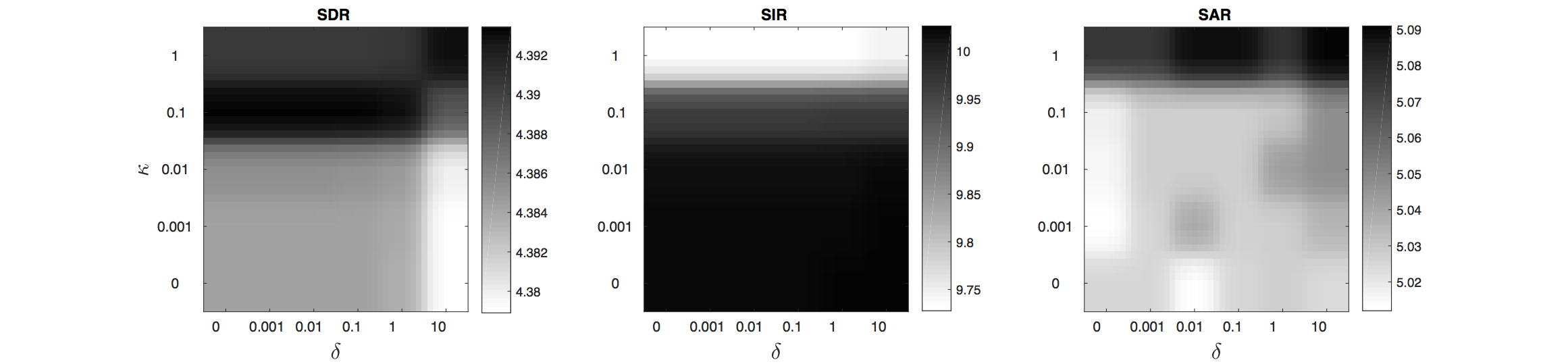
We also present a graphical illustration of the separation performance of the CAW filtering. This filter depends on a parameter $\kappa$ that promotes the "sinusoidality" of the signal (through the phase unwrapping technique) and a parameter $\delta$ that promotes the consistency constraint.
Acknowledgements
We would like to kindly acknowledge all those that supported and helped us for this work.
- P. Magron is supported by the Academy of Finland, project no. 290190.
- Part of the computations leading to these results was performed on a TITAN-X GPU donated by NVIDIA to K. Drossos
- Part of this research was funded by from the European Research Council under the European Union’s H2020 Framework Programme through ERC Grant Agreement 637422 EVERYSOUND.
- P. Magron, K. Drossos and T. Virtanen wish to acknowledge the CSC-IT Center for Science, Finland, for computational resources
- S.-I. Mimilakis is supported by the European Union's H2020 Framework Programme (H2020-MSCA-ITN-2014) under grant agreement no 642685 MacSeNet